L’entrada d’avui és a càrrec del Dr. Marc Ribó, bioquímic de la Universitat de Girona.
Marta Planas
La comprensió de la relació estructura-funció de les proteïnes i com aquestes interaccionen amb altres biomolècules resulta clau per entendre els mecanismes moleculars que hi ha darrera els processos biològics.
La majoria de les proteïnes estan modificades post-traduccionalment en un o diferents residus aminoacídics amb la finalitat de modular la funció de la proteïna ja sigui, a nivell de la seva conformació o de la seva activitat. És més, moltes proteïnes poden ser modificades de moltes maneres diferents, com per exemple les histones dels nucleosomes en la cromatina, en les quals s’han descrit una dotzena de modificacions diferents i les quals constitueixen un dels focus d’estudi de l’epigenètica.
És tal la magnitud d’aquestes modificacions post-traduccionals, que establir un catàleg acurat del proteoma d’un organisme resulta una tasca molt feixuga perquè l’inventari hauria de recollir quins gens s’expressen i com es modifiquen post-traduccionalment les proteïnes codificades per aquests gens, segons el tipus cel·lular o el teixit, i al mateix temps, com aquests patrons varien al llarg d’una escala de temps biològica que oscil·la entre els pocs minuts, per exemple en la transducció d’un senyal hormonal, i uns quants anys, en cas del nostre desenvolupament com a organismes. Aquesta diversitat imposada per la naturalesa fa extremadament difícil obtenir per sistemes de purificació estàndard, a partir de cultius cel·lulars o de teixits, preparacions homogènies d’una determinada proteïna amb unes determinades modificacions post-traduccionals concretes.
Després de la química de proteïnes convencional, el desenvolupament de les tecnologies de DNA recombinant, la mutagènesi dirigida i l’expressió heteròloga de proteïnes, han permès la producció d’un gran nombre de proteïnes, anomenades variants, en les quals un o diversos residus de la cadena polipeptídica han estat substituïts per altres residus aminoacídics en posicions concretes i definides. La caracterització de l’estructura i la funció d’aquestes variants proteiques i la comparació amb la proteïna salvatge, ha permès donar resposta a molts dels interrogants plantejats sobre determinats problemes biològics.
Tanmateix, aquestes estratègies estan limitades a la utilització dels 20 aminoàcids codificats a nivell d’àcids nucleics i en alguns casos pot ser imprescindible o interessant obtenir proteïnes amb una modificació post-traduccional concreta o només en una posició específica de la cadena polipeptídica, introduir aminoàcids no naturals o sondes biofísiques que ens permetin respondre amb més precisió i exactitud a les hipòtesis plantejades.
En principi, una aproximació essencialment química permet generar un nombre il·limitat de proteïnes modificades. El desenvolupament, optimització i automatització de la síntesi de pèptids en fase sòlida (SPPS) permet la síntesi rutinària de pèptids de 50-60 residus de llargada, i la incorporació de modificacions post-traduccionals com fosfats, lípids o sucres o d’aminoàcids no naturals en aquests pèptids sintètics.
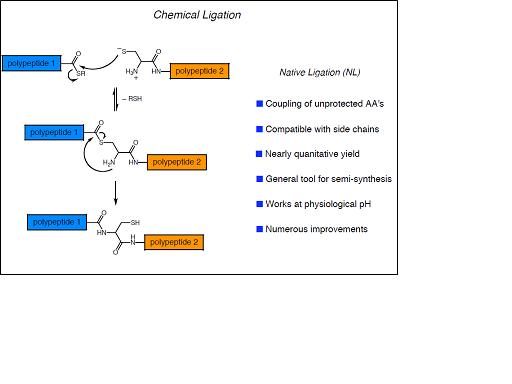
La limitació fonamental en la longitud dels pèptids sintètics pot resoldre’s mitjançant reaccions de lligació quimio-selectives en les quals dos o més pèptids no protegits poden ser units. Una de les estratègies que ho fan possible és l’anomenada ‘Native Chemical Ligation’ (NCL) mitjançant la qual un pèptid no protegit amb una cisteïna N-terminal pot reaccionar amb un segon pèptid amb un tioéster C-terminal. Tanmateix, la restricció imposada per la longitud dels pèptids sintètics, juntament amb la dificultat per dur a terme múltiples etapes de lligació seqüencials limiten, ara per ara, aquesta aproximació a proteïnes de mida petita.
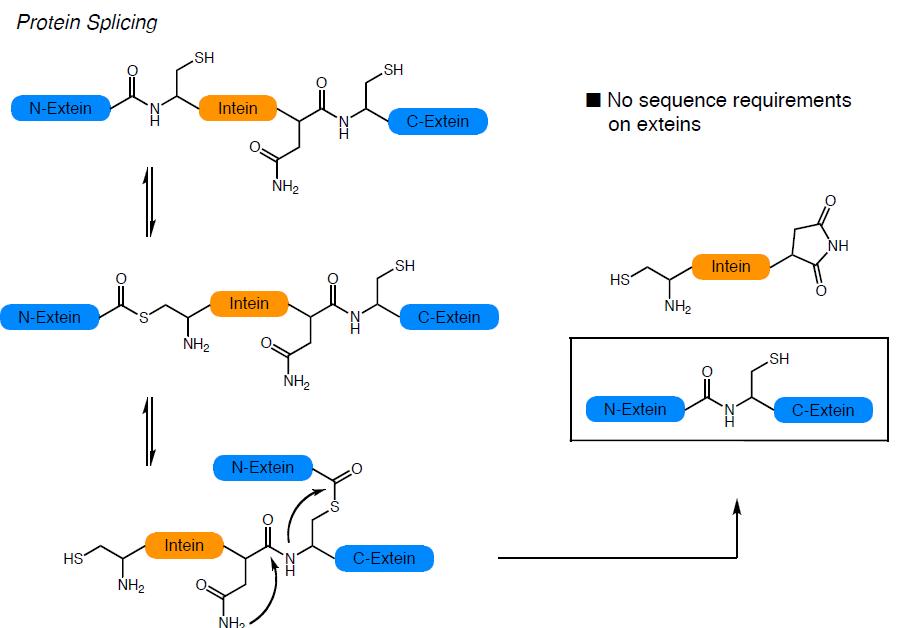
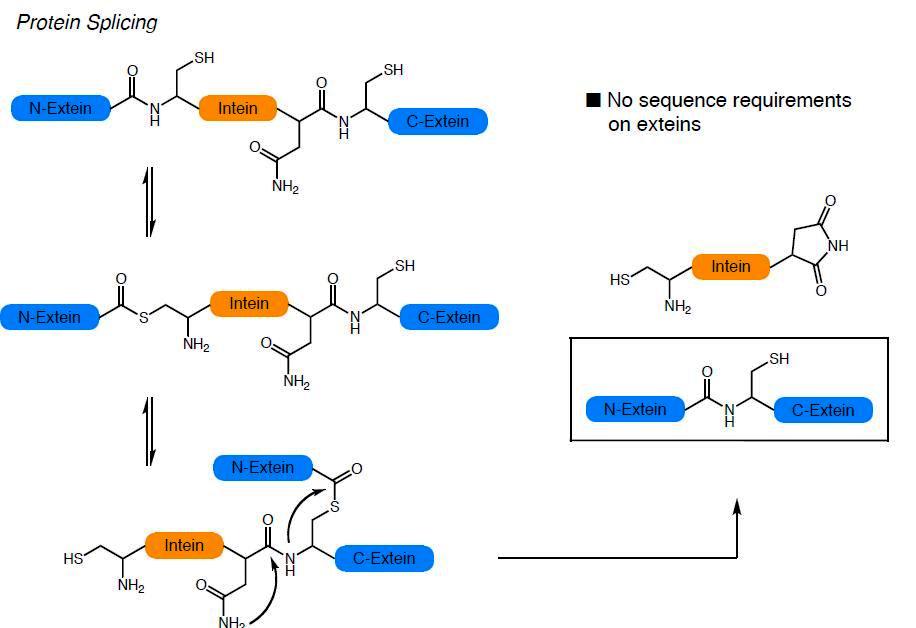
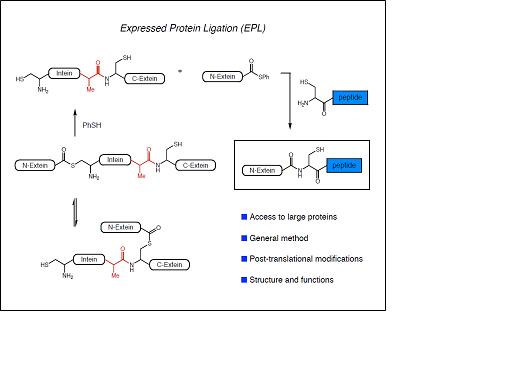
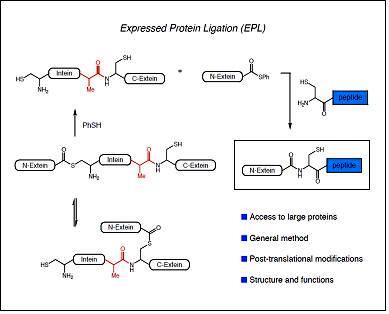
 La combinació de la NCL amb les tècniques de producció de proteïnes heteròlogues recombinants ha donat lloc a la anomenada ‘Expressed Protein Ligation’ la qual ha permès la incorporació de modificacions post-traduccionals i aminoàcids no naturals a proteïnes de mida mitjana o gran. La EPL resulta de la convergència de principis químics i biològics: té les seves arrels tècniques i conceptuals en la química orgànica i la síntesi de pèptids i s’inspira en un procés biològic descobert el 1990 anomenat ‘protein splicing’. En aquest procés, anàleg al que té lloc en la maduració dels RNA, un segment de la cadena polipeptídica precursora anomenat inteïna, s’autoescindeix de les regions N- i C-terminal que el flanquegen anomenades exteïnes, les quals s’uneixen finalment mitjançant un enllaç peptídic natiu, donant lloc a la proteïna funcional.
La combinació de la NCL amb les tècniques de producció de proteïnes heteròlogues recombinants ha donat lloc a la anomenada ‘Expressed Protein Ligation’ la qual ha permès la incorporació de modificacions post-traduccionals i aminoàcids no naturals a proteïnes de mida mitjana o gran. La EPL resulta de la convergència de principis químics i biològics: té les seves arrels tècniques i conceptuals en la química orgànica i la síntesi de pèptids i s’inspira en un procés biològic descobert el 1990 anomenat ‘protein splicing’. En aquest procés, anàleg al que té lloc en la maduració dels RNA, un segment de la cadena polipeptídica precursora anomenat inteïna, s’autoescindeix de les regions N- i C-terminal que el flanquegen anomenades exteïnes, les quals s’uneixen finalment mitjançant un enllaç peptídic natiu, donant lloc a la proteïna funcional.

La mutació de la inteïna en determinades posicions, permet que el precursor proteic quedi atrapat en un equilibri entre el tioéster i la forma amida. La inteïna modificada pot ser alliberada pel tractament amb tiols generant una proteïna recombinant amb un tioéster C-terminal. Aquest grup de la proteïna obtinguda de manera recombinant pot ser utilitzat per a lligar-hi un pèptid sintètic amb una cisteïna N-terminal obtenint així la proteïna semisintètica.

En la revisió publicada l’octubre del 2010 a Cell per M. Vila-Perelló i T. W. Muir (Cell, 2010, 143, 191-200) , es presenta una recopilació de les possibilitats i el potencial de l’EPL i el protein splicing per a la introducció de modificacions post-traduccionals o aminoàcids no naturals en posicions específiques de les proteïnes i, en definitiva com la química biològica ha permès l’expansió del codi genètic i aprofundir en el coneixement dels processos biològics.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
gener 31st, 2011 → 10:53 am
[…] This post was mentioned on Twitter by Jordi Poater, Jordi Poater. Jordi Poater said: Conegueu com es sintetitzen les proteïenes a @catquimica http://ves.cat/arBW #aiq2011 […]